正好整理东莞1馆的借阅数据,因此也把过程复刻下来,主要是依赖几个基本功能,另附几个好用省时的小技巧,就可以按自己的需求分析和汇总数据
有需要的伙伴,供参考。
一、益迪云图下载数据
网页版地址: https://yuntu.yidivip.com/
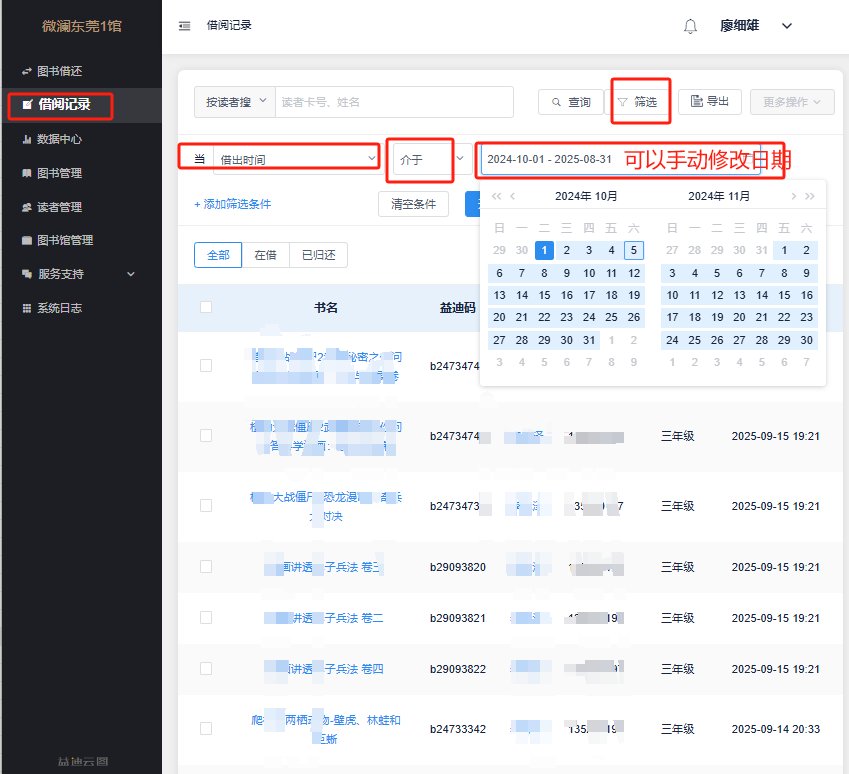
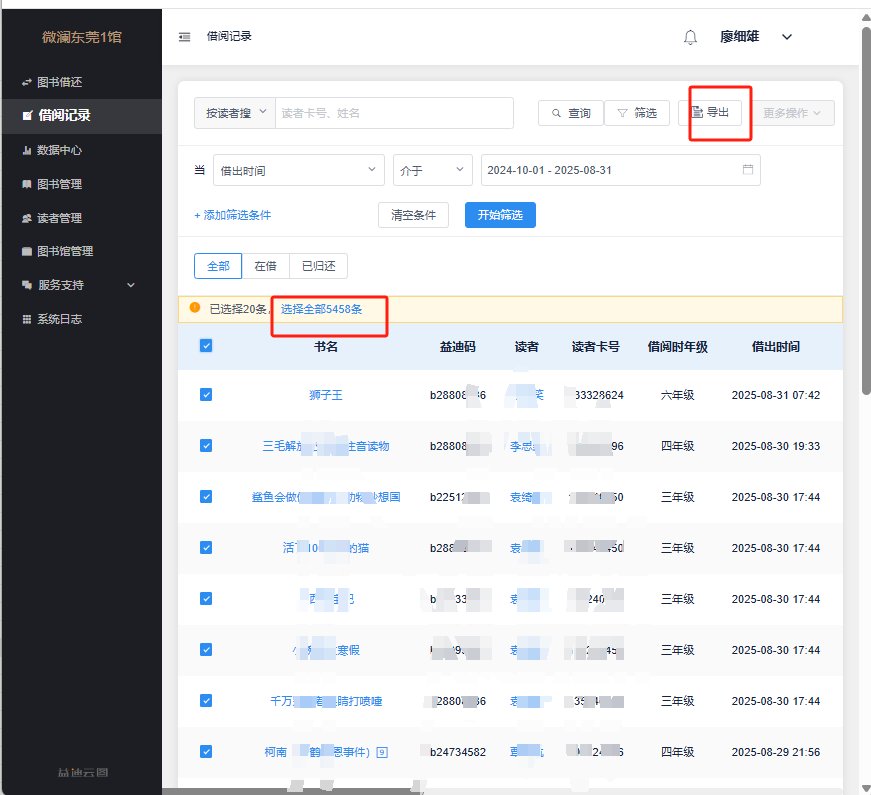
图书,读者数据,下载方法都如上,筛选,全选
二、读者借阅情况分析
2.1 利用 数据透视表功能,统计各年级 借阅册次

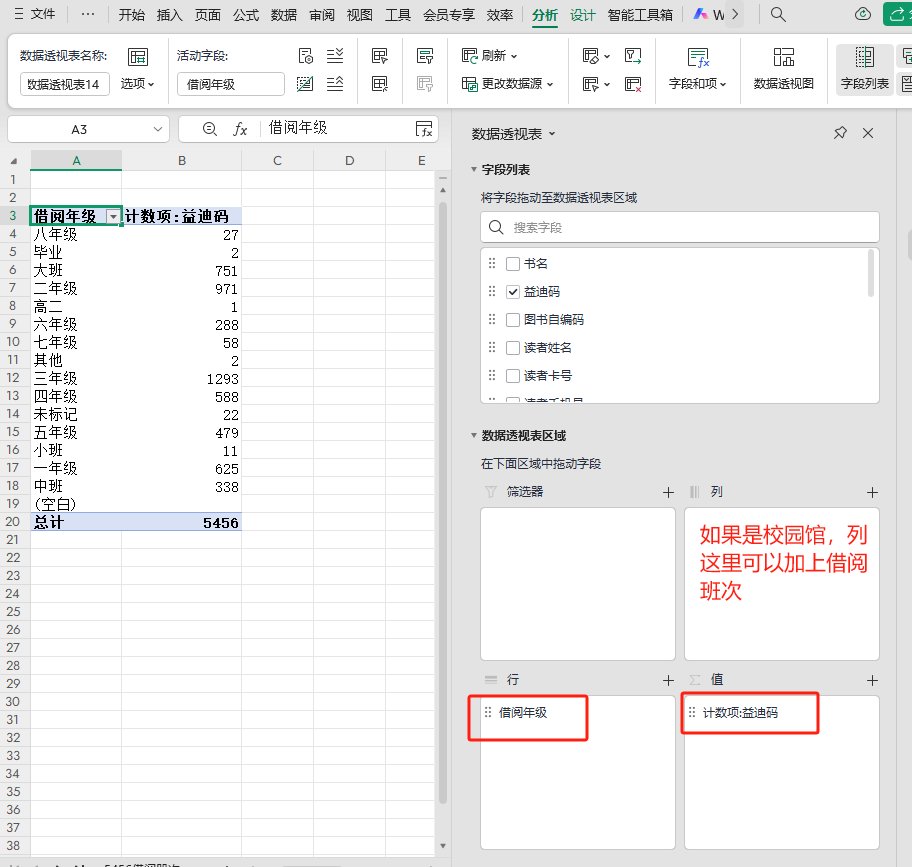
2.2 利用重复项 计算统计期内参与借阅读者 和,利用 数据透视表 功能,统计各年级借阅读者人数
2.2.1 利用重复项 功能,计算统计期内参与借阅读者
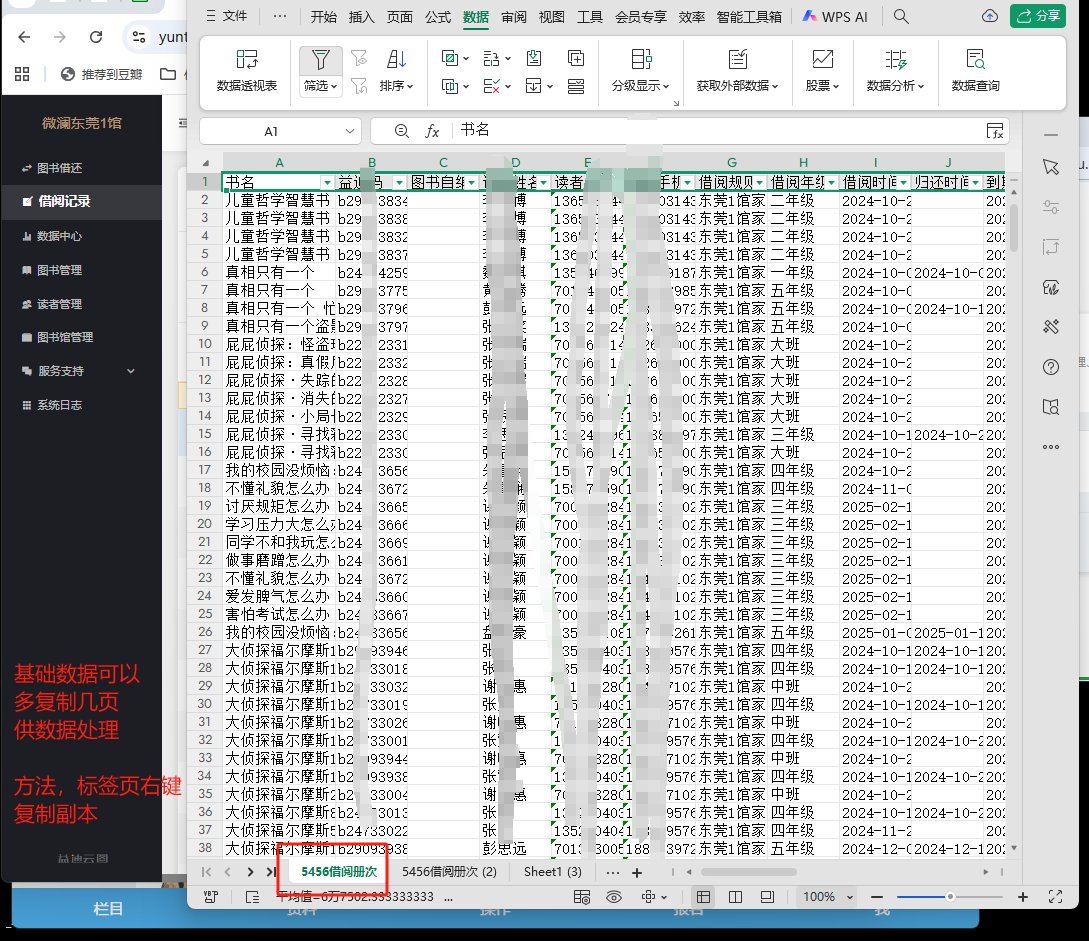
一般会创建副本,基础数据保留,在副本上操作
如下:
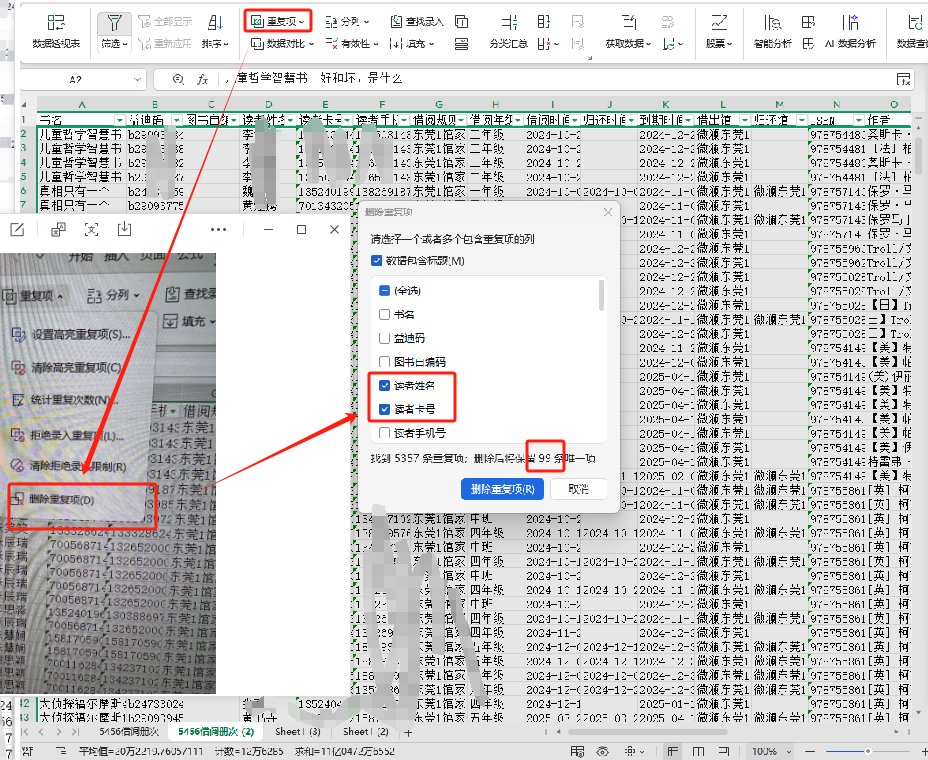
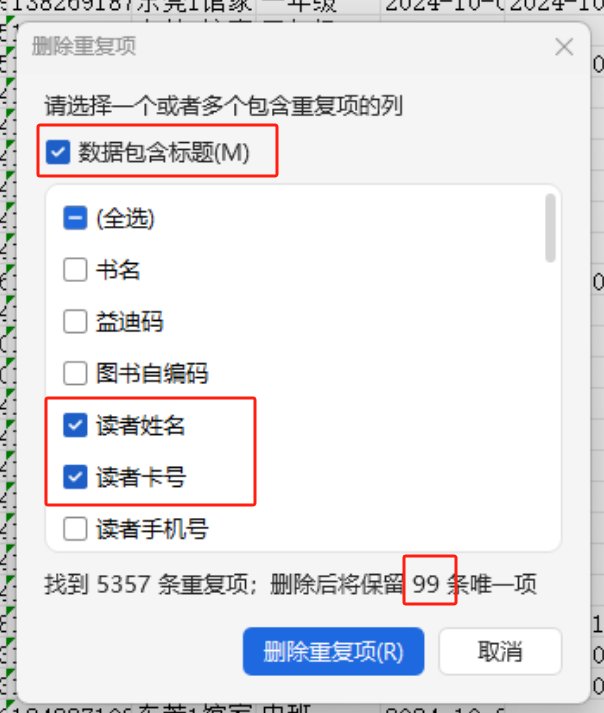
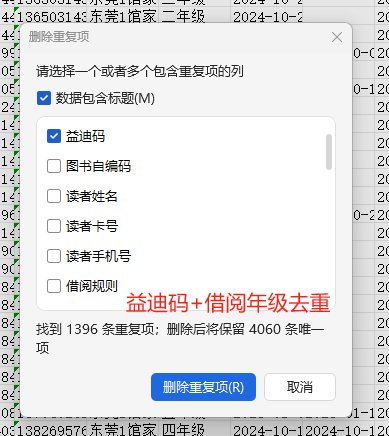
为避免删除了同名读者,这里可以只按读者卡号去重,或 读者姓名+卡号去重,结果其实一样的
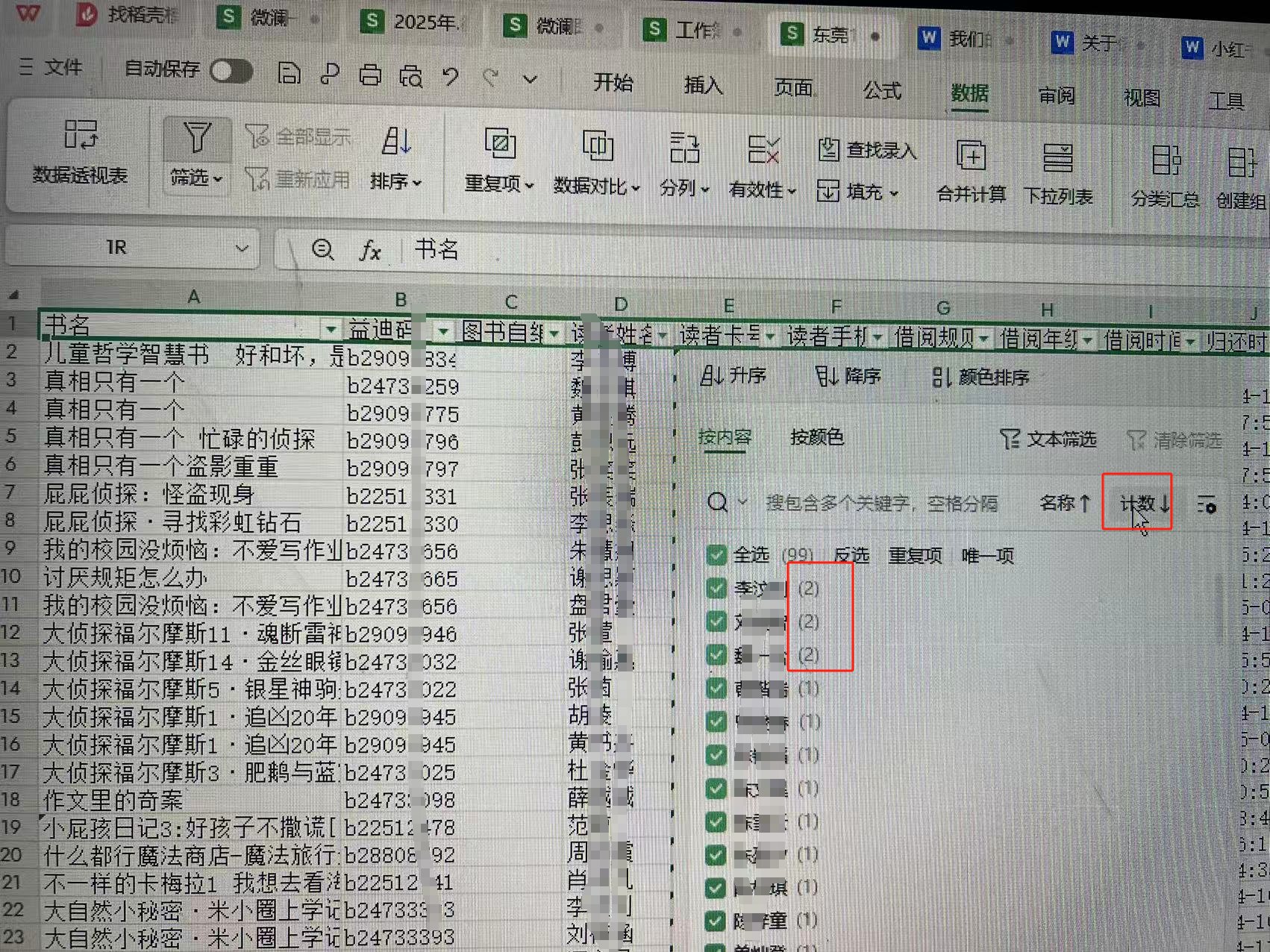
去重后的数据表只剩下99条数据,可以利用 #筛选 的 #计数排序,很方便找出同名作者,经过比对,实际是三个读者一人多卡(这也是整理数据的意外,可以非常容易排除我们的误操作或发现各种问题,然后对应进行处理)
2.2.2 去重结果上,利用 数据透视表 功能,统计各年级借阅读者人数, 和2.1 统计结果数据合并
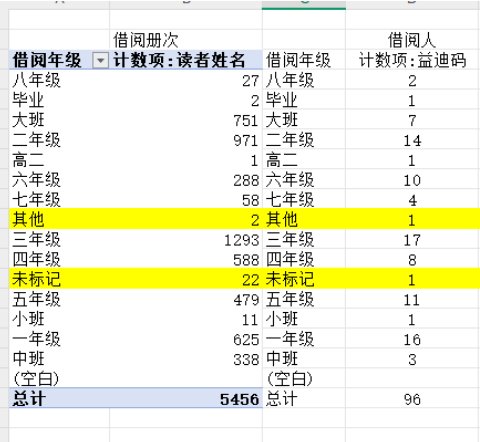
2.3 回到完整初始数据的另一个副本,利用重复项去重功能 和 数据透视表,把借阅数据按 借阅年级+ISBN 去重
去重结果在数据透视表上 按借阅年级统计
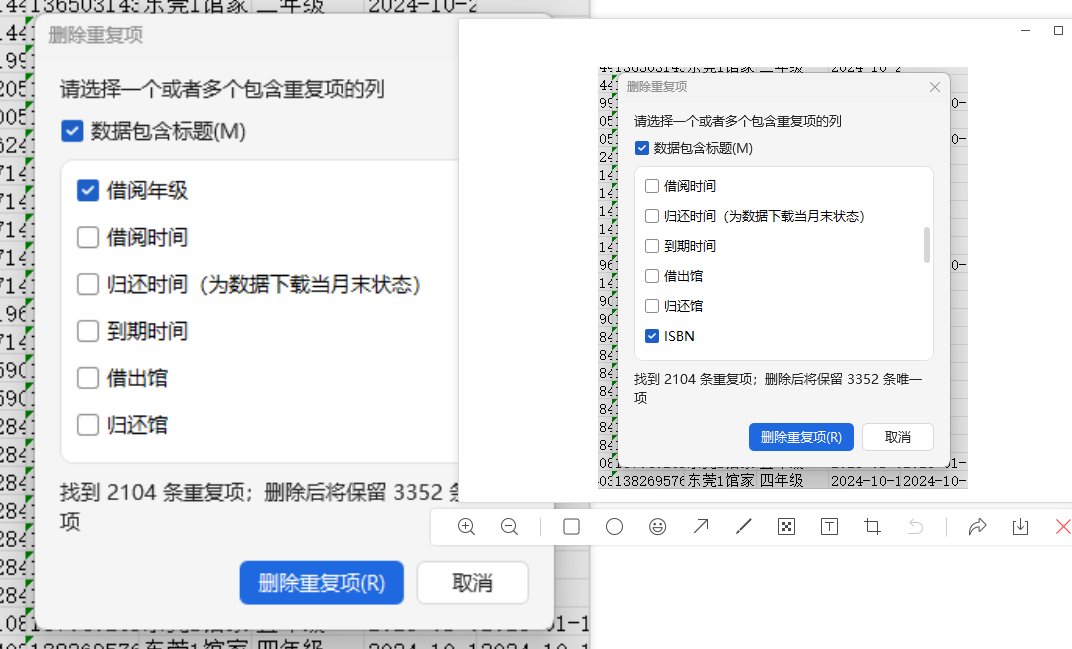
2.4 回到完整初始数据的另一个副本,利用重复项去重功能 和 数据透视表,把借阅数据按 借阅年级+益迪码 去重
去重结果在数据透视表上 按借阅年级统计
统计结果合并,其中,2.3,2.4 去重后数据再分别按 ISBN码 和益迪码 再去重,得出全馆 不分年级去重后的 ISBN码 和益迪码 数量,如图
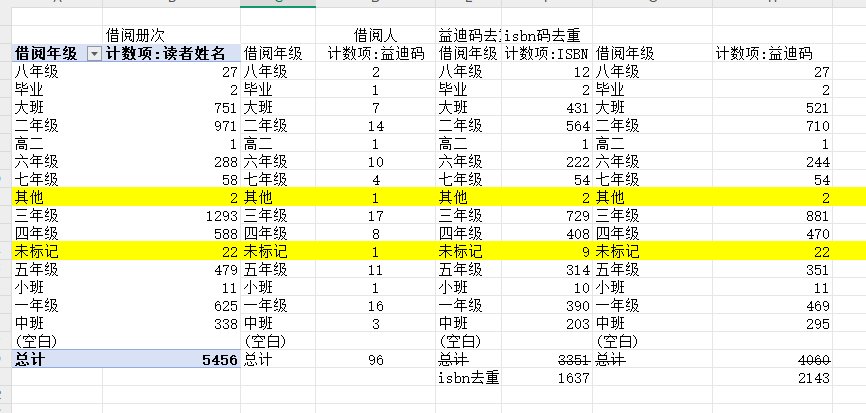
发现其他和未标记数据在不同的统计中,其他也是未标记,合并成一行
以上数据进行整理,得出数据图为
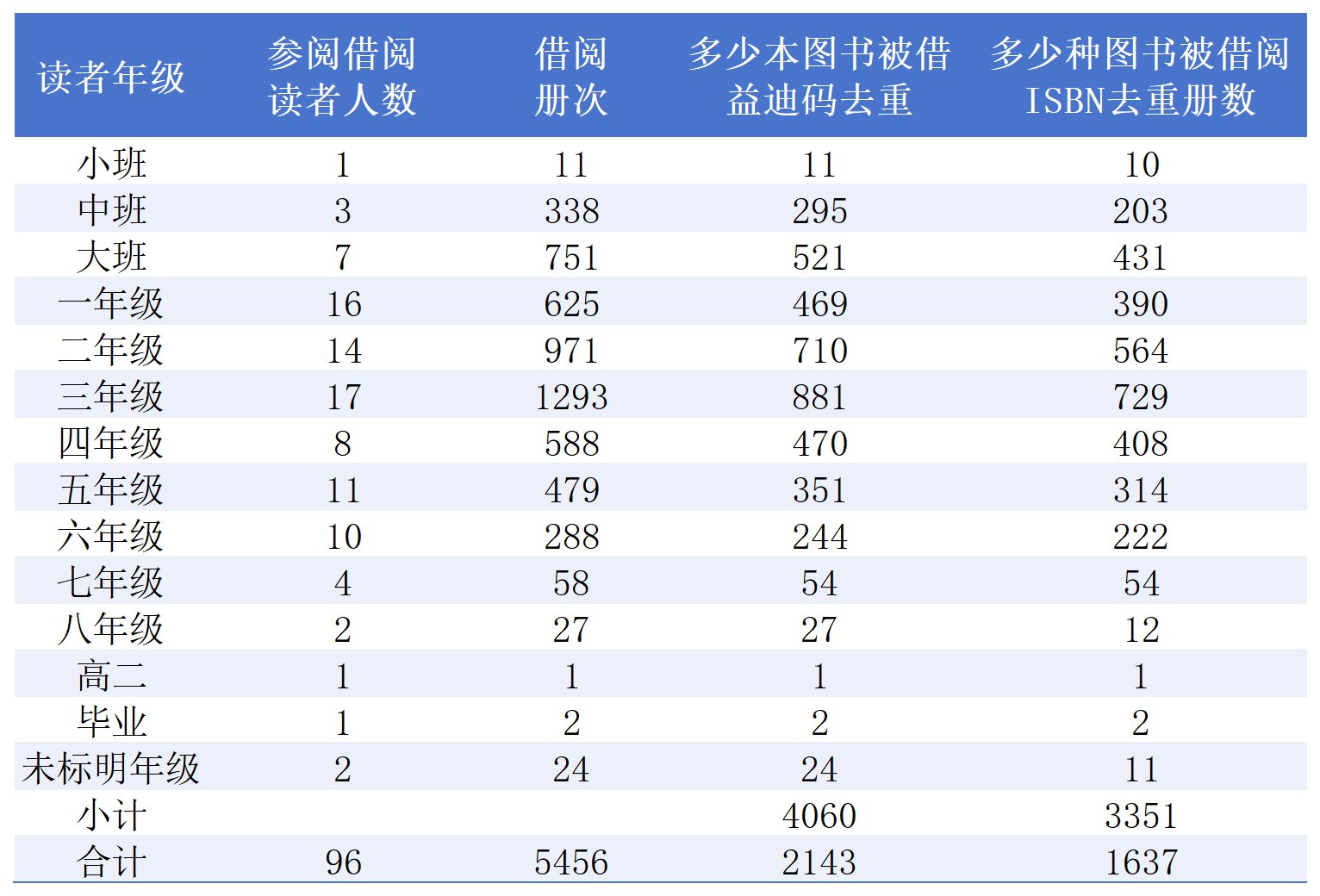
2.5 利用基础书,利用数据透视表功能,按读者进行统计,查看借阅读者借阅情况
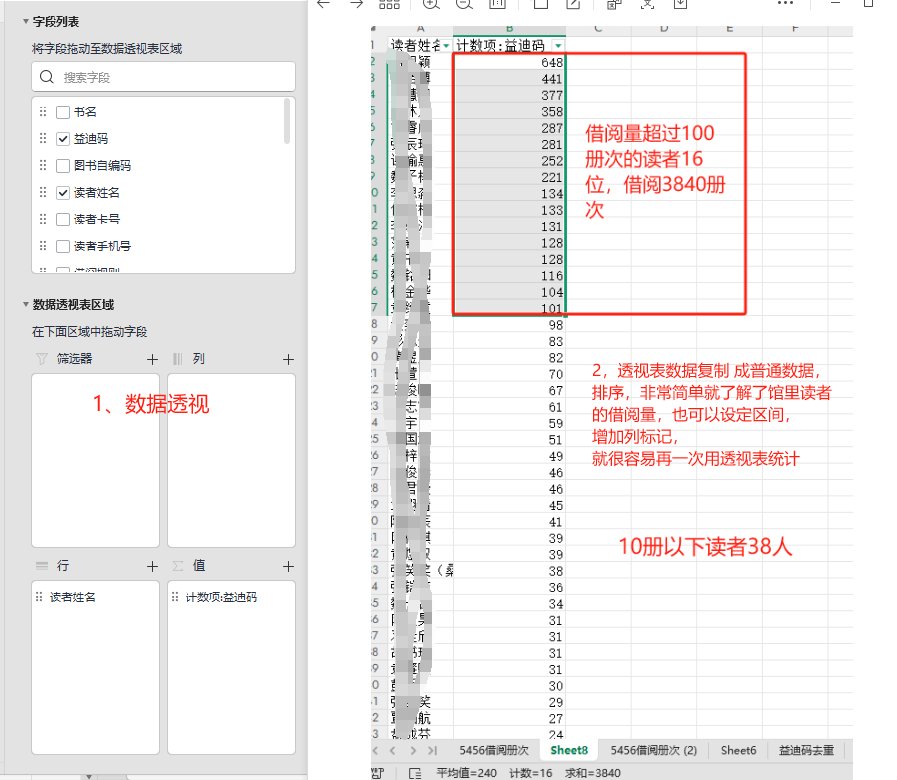
比如微澜图书馆数据报告中数据,就是按以上方法得出

三、图书被借阅情况分析
3.1 借阅数据 利用数据透视表,进行统计
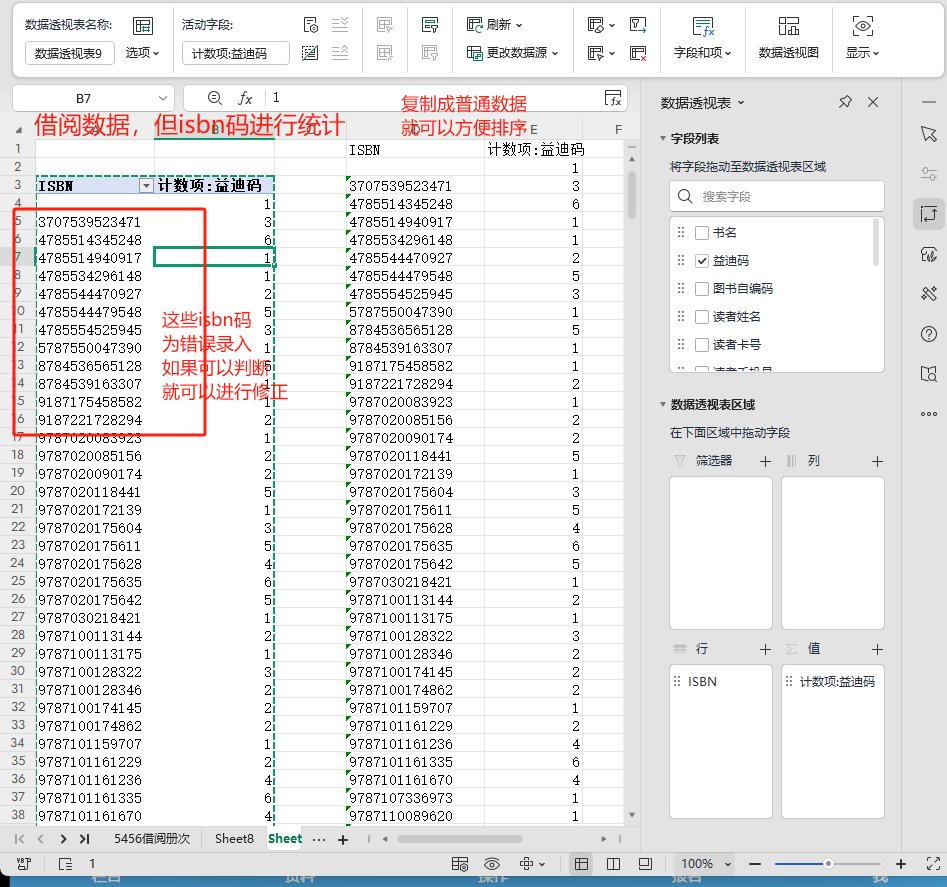
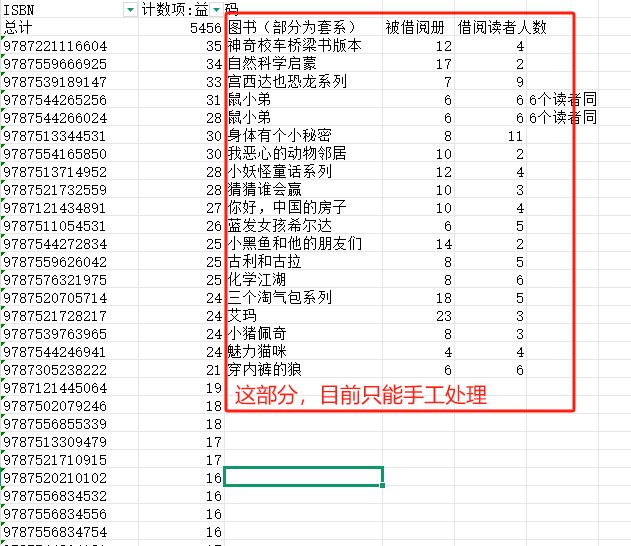
排版优化以后,但查阅基
础数据,因为图书的isbn码,有的一个码对应多本书,有的一套书每一本都有码,因此,这个排行本身是不太可靠的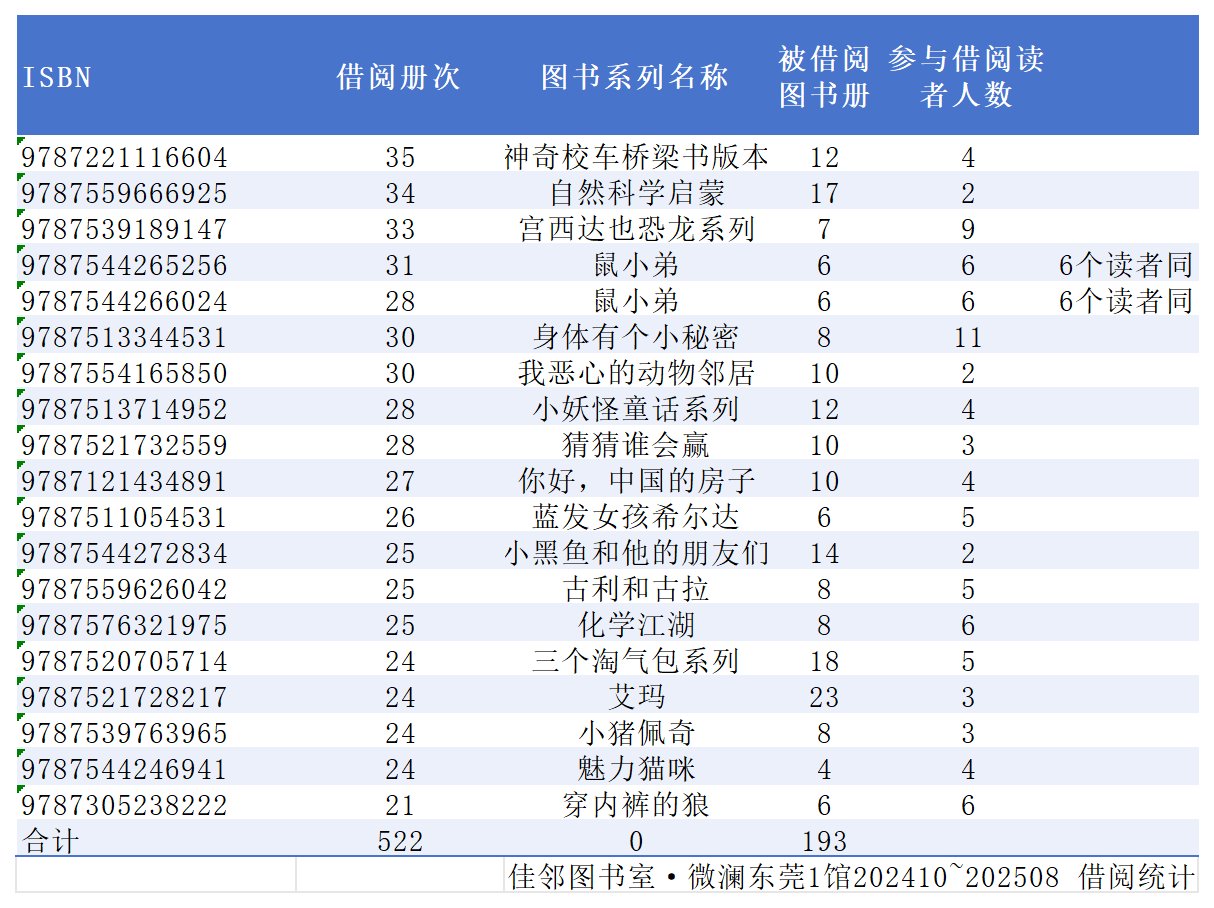
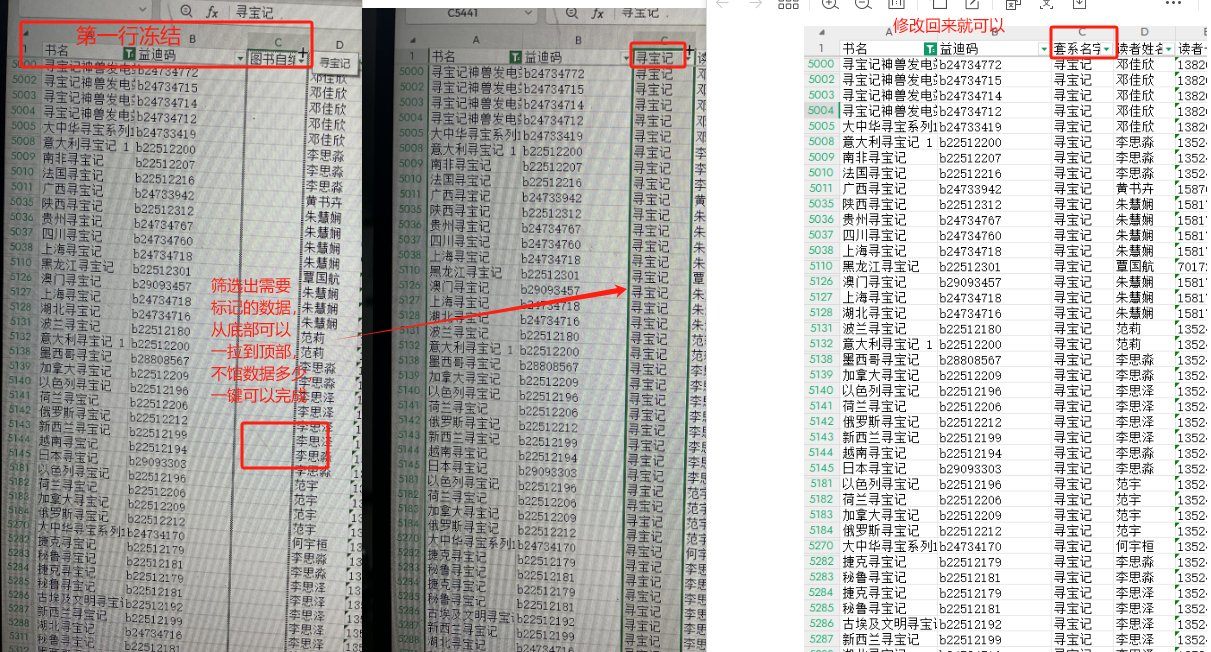
3.2 对套系数进行标记,后进行统计
以下是标记,然后利用计数功能排序显示
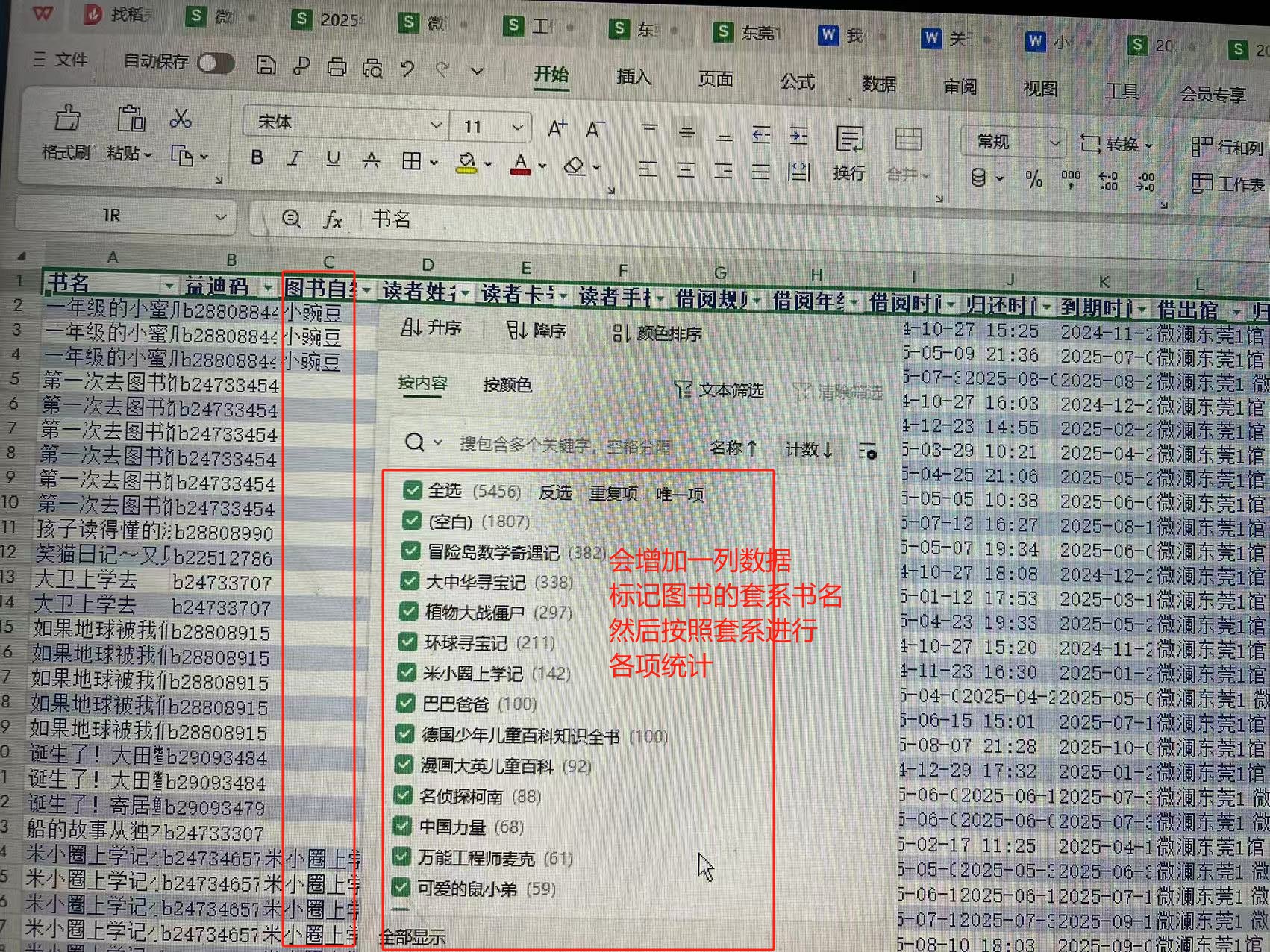
重复2.2的各项过程
1、标记套系 列的数据,直接按 套系 排名,然后利用数据透视表按套系统计 每套系总的被借阅册次
2、标记套系 列的数据,可以根据借阅读者去重,然后利用数据透视表按套系统计
3、标记套系 列的数据,根据益迪码去重(这里有一个假定,因为这是一个馆的,假定每本书只有一本),然后利用数据透视表按套系统计
三个统计结果合并到一张数据表中
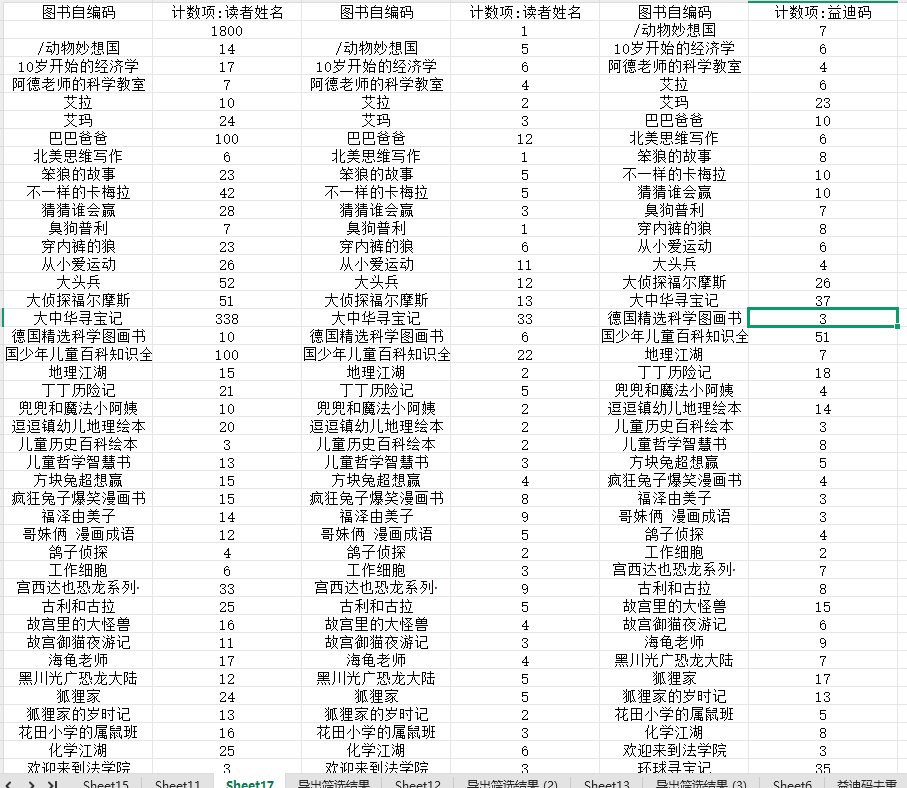
对齐,排序,
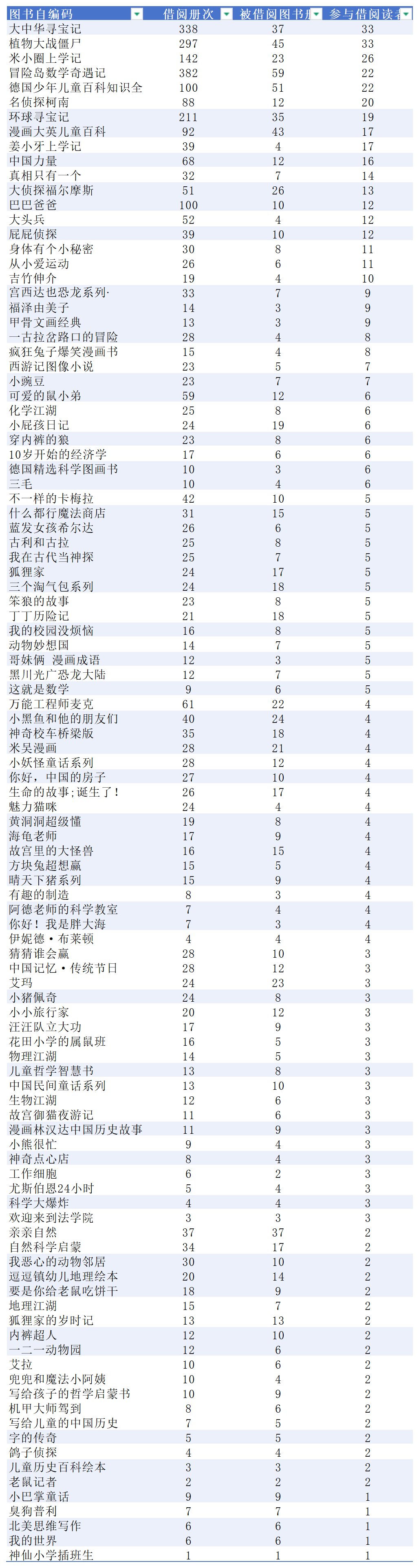
根据需求增加其他指数(按参与借阅读者排序,这里只显示前40套):
五个维度,可以按不同的维度排序,看看结果如何
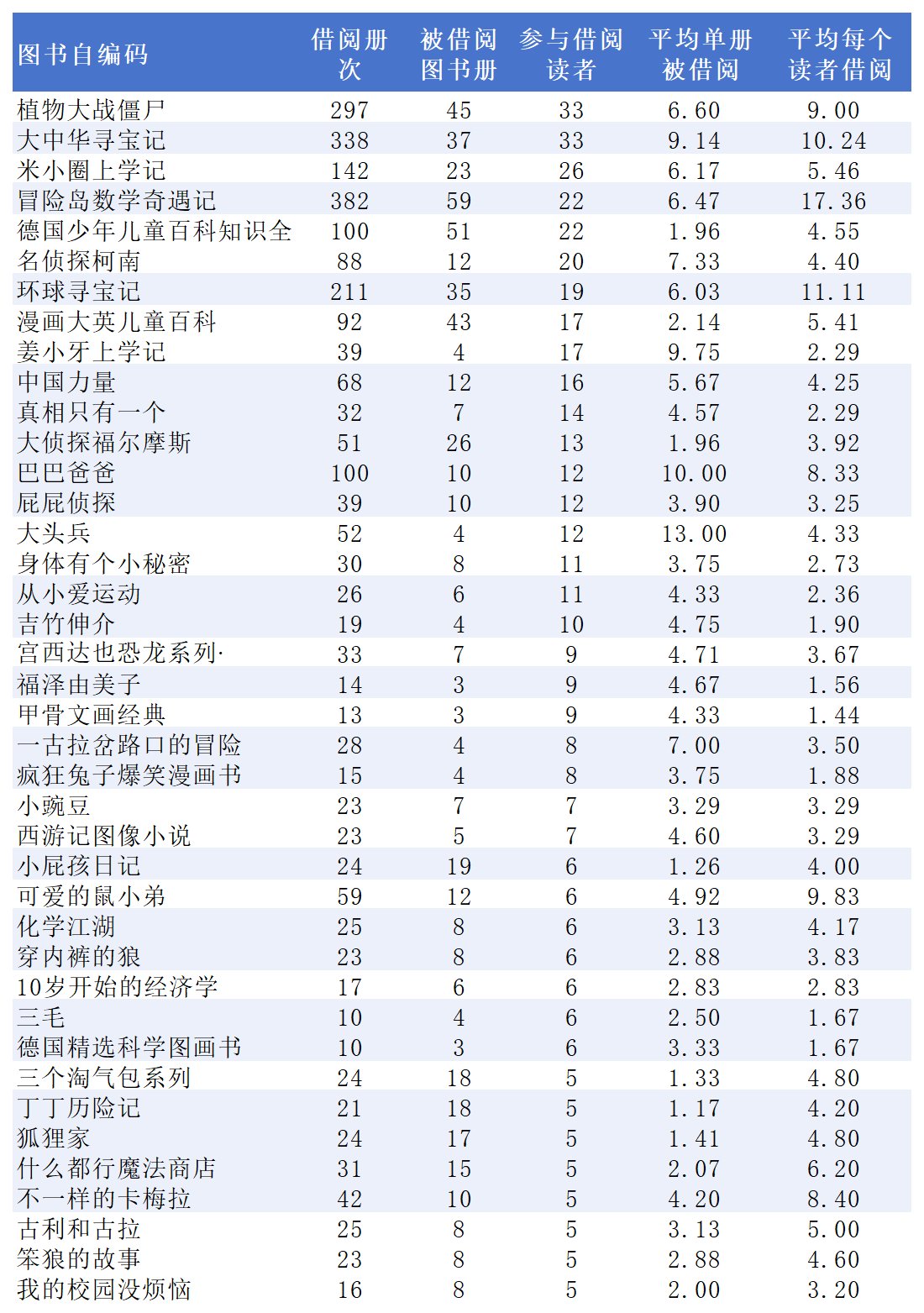
四、一些其他的常用功能
分列,分列功能处理信息,比如时间,很容易按年,或者月,甚至日进行数据统计和分析
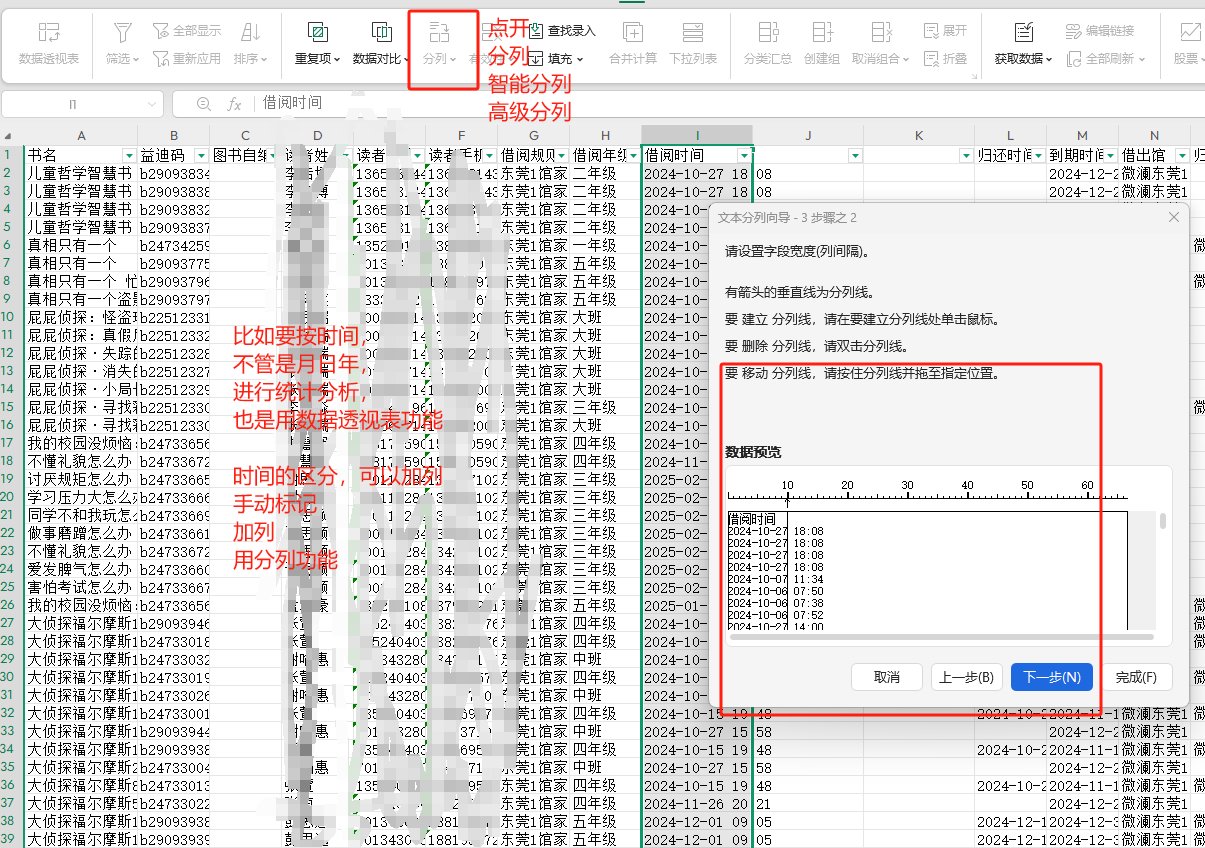
五、当我们初始数据很多,只需要对其中一部分进行分析处理时,先筛选出该部分数据,然后筛选下拉菜单-导出筛选结果,就可以很方便把这部分数据分离出来
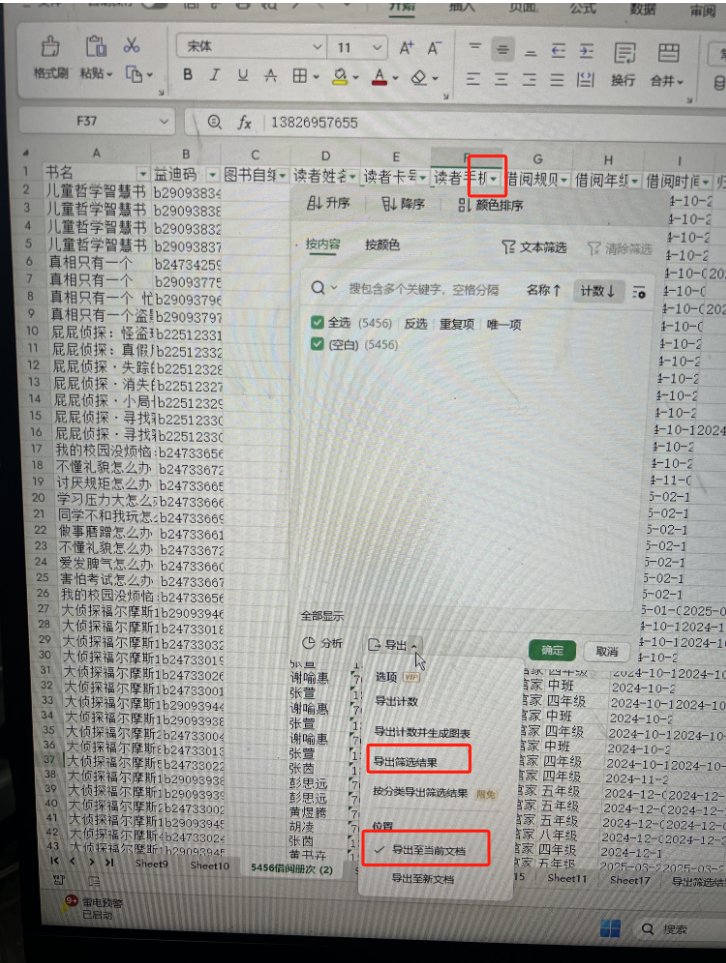
六、当你有的分析方法和维度,基础数据没有,增加列,进行标记就可以
增加列,标记,冻结第一行,标记数据